

From a million invocations to thousand with correct caching
First, the results
A journey on how I went from that amount of invocations in a voting system:
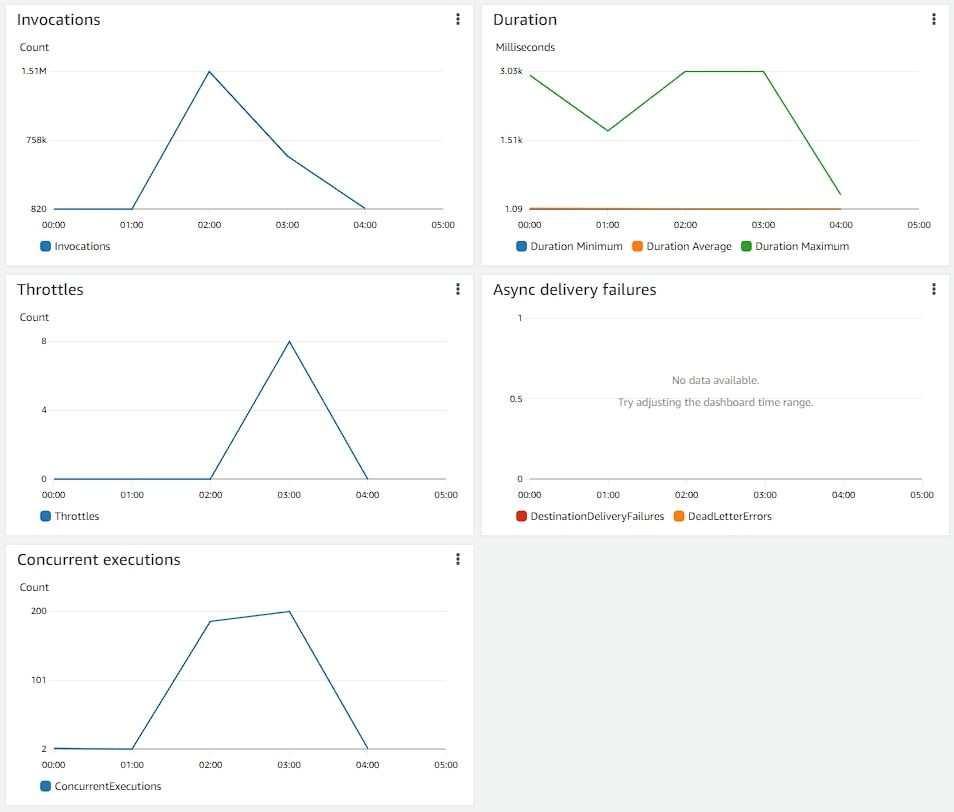
For that number of invocations, making 2x as many requests as the v1 metrics, but processing only a fraction of them:
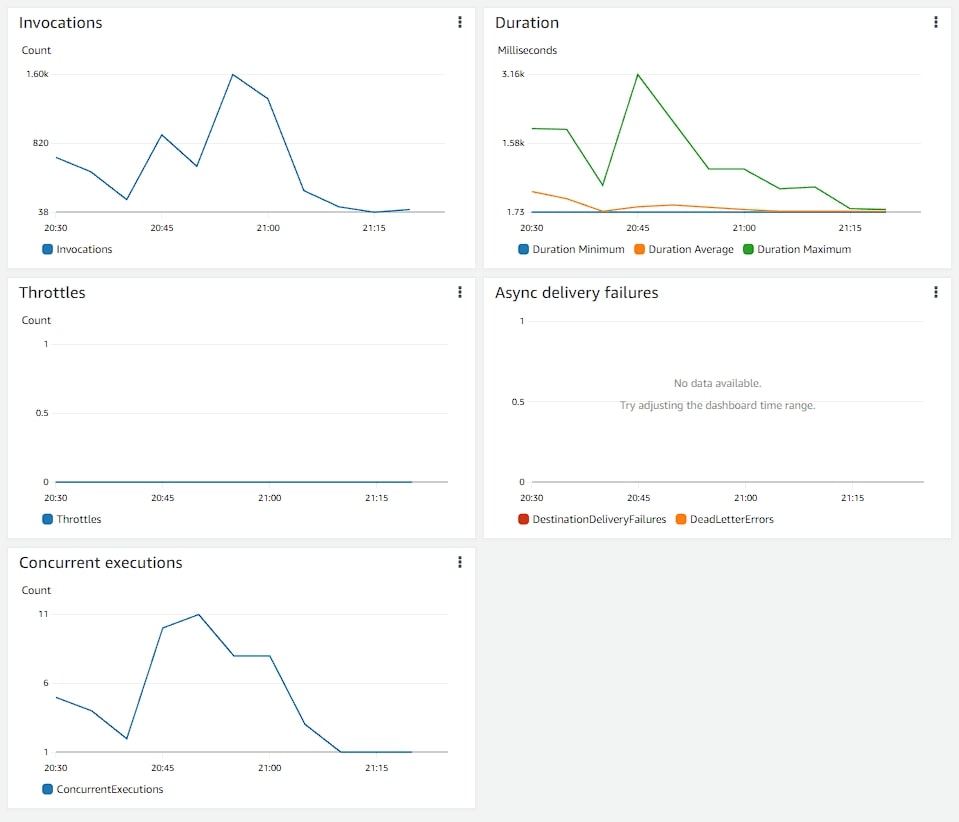
If you don't like reading images, don't worry, I have a table:
| Version | Votes | Invocations (peak) | Lambda Concurrency (peak) |
|---|---|---|---|
| v1 | 280k | 1,51 million | 200 |
| v2 | 700k | 1,6 thousand | 11 |
Well, I can say that it's definitly a blazing fast improvement, right?

Ok, context please?
Okay, the following task came to me one Monday morning:

With these requirements, let's present the first architecture I developed.
v1 Architecture
About the technologies, I chose:
- NestJS with Fastify.
- For performance, I leave as little middleware as possible, I even removed
compressionandrate-limitto not cost too much in performance.
- For performance, I leave as little middleware as possible, I even removed
- Stateless JWTs to authenticate.
- I usually prefer to hit the database on every request to check if the JWT is still valid, in this case I skip this part and keep the JWT expiry time as low as possible.
AWS Lambdafor hosting the code.- The advantage of using this guy is that I can only pay for usage, and the TV show only runs once a week, so this guy fits in really well.
AWS API Gateway HTTPto exposeAWS Lambda- Using
HTTPversion instead ofRESTmakes me reduce costs, instead of paying $4 per million, I only pay $1.
- Using
AWS ElastiCacheto cache all data to reduce database workload on hot-paths.- I choose a cluster with 2 instances of 0.5GB, I won't save much information but I need to have a high reading capacity.
AWS RDS Postgresas the database service.- For this guy, I knew I wouldn't use that much, so I just chose a T4g.small with 2vCPU with 2GB of RAM.
The architecture looks like:
Fun fact: It cost around $70 without any API calls.
But wait, why didn't you choose X over Y?
At this point, you might wonder why I didn't use a NoSQL database, or host on AWS EC2, or use another technology.
My answer to this is just this: I had 2 weeks to build a system, test it and deploy it to be used by the TV show.
Also, I'll explain later, it makes almost no difference what technology I choose for the database, for hosting the API, the main bottlenecks of my application not in those areas.
Choose technologies that your team is comfortable with and you know, if you have more time you can explore and test new things but with little time, go with technologies that you already deployed in production and those were the technologies that I was aware of at the time.
The hot path of V1
Hot Path is the area of your code that is most accessed, in my case it was two routes:
GET: /polls
This route returns current polls for users to see which singer is currently up for voting.
To have better performance and not hit the database every time, I store this data inside the ElastiCache,
so every time someone asks for the open polls, I return this data which has been cached for 3s until needs to get from the database.
This cache was inside the AWS Lambda, inside the NestJS service that handles the request to obtain the polls.
Remember this information, I'll talk about it again in the V2 architecture.
Also, this route was called every 3s by users because we need to check if the poll is still available, administrators can enable and disable them at will.
POST: /polls/{pollId}/signers/{signerId}
In this route, users can select which singer they want. And since the user can call this route as many times as he wants, this route is insanely called.
To decrease the stress on the database, I only make 1 database call on this route, it's the insert to save the vote.
To count the amount of votes, I leave that task to ElastiCache and use this insanely well-designed library called redis-rank.
With this library, I could easily rank each poll and input the votes one by one as it arrives.
To check if the vote is valid, I cache the information in ElastiCache and just look it up. With this strategy, I was able to save 2 database calls, one
for pollId and another for signerId.
The downside to this strategy is that I have to create hooks in all the methods that change the poll and signer to update the cache. An easier way to do this is by emitting an event for each change, so you just have to listen to the changes to be able to update the cache.
For the table that saves the votes, I didn't use foreign keys because I didn't want the database to do the work it already did of verifying that the information
its valid. Also, I chose this strategy for performance reasons, Adam Zolo has an article on The Cost of PostgreSQL Foreign Keys if you are interested.
For this table, I left only an index in pollId so I can count and compare the votes once the poll is over to check if everything is in sync.
The metrics of V1
At this point I was really proud of what I was able to achieve because I deploy this solution and it worked really well.
Now, let's see the metrics of 280k votes performed by 12k users:

In addition, I also have some database metrics:
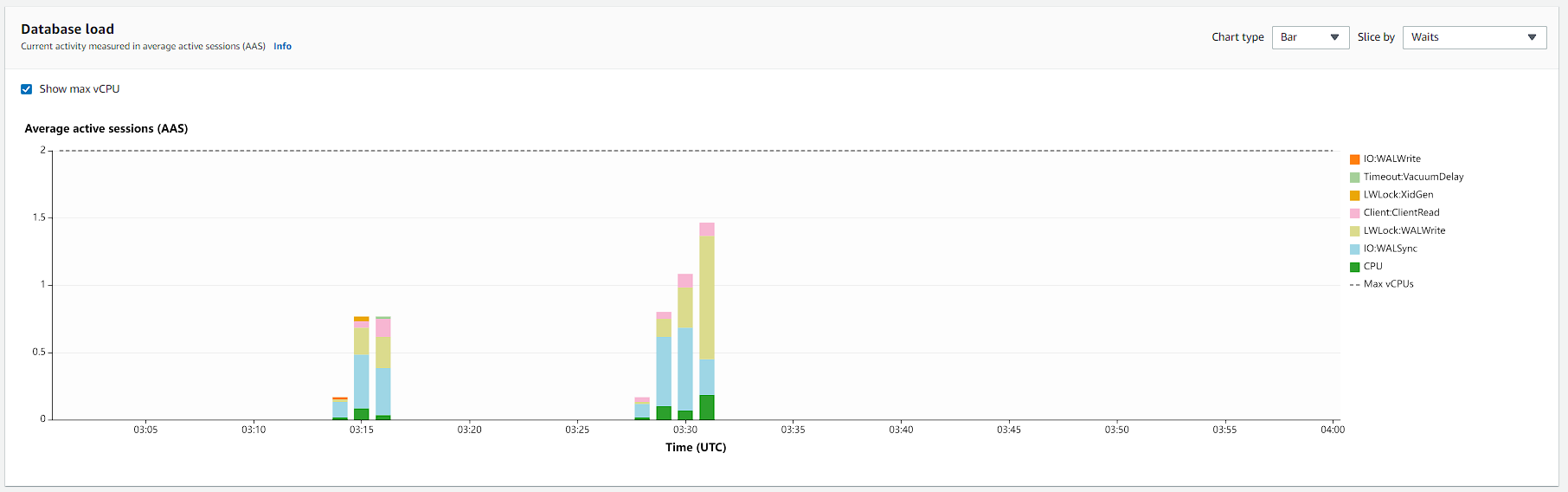
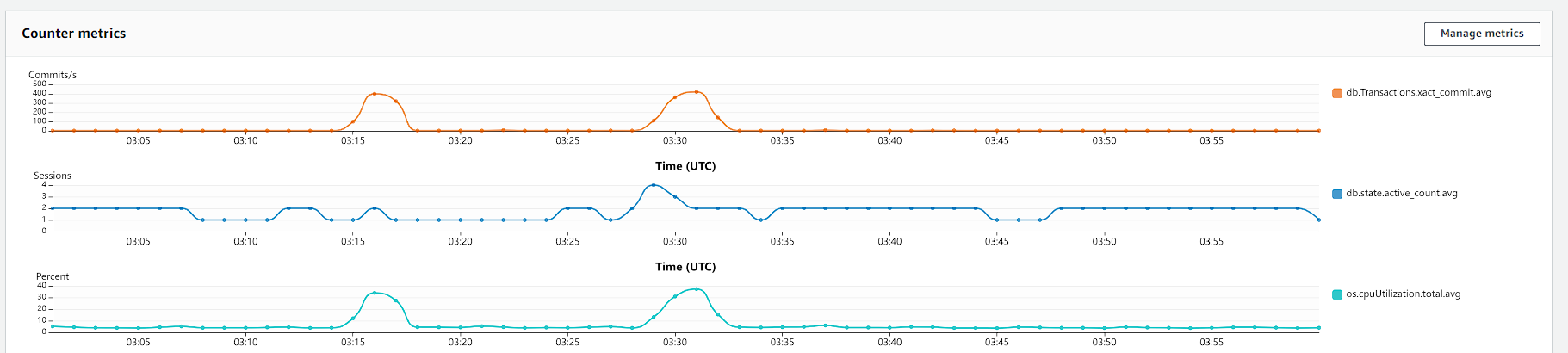
Hint: Click on the image to open in higher resolution.
The system was very stressed, but it worked very well (no errors). The CPU usage was high but it is scalable so it can pass 2 vCPU without any worries so this amount of usage is not an issue.
The only thing I didn't like is the amount of concurrency in lambdas and the amount of commits per second, the database was doing like 400 commits per second, it's A LOT.
The architecture wasn't bad, but I wasn't happy with those numbers, the system wasn't scalable enough for me, so I started looking into other approaches to the same problem.
The optimal number of lines of code is zero
Maybe you've heard this phrase somewhere before, this phrase stuck in my head during my studies and then I started thinking of strange solutions.
One such solution was: What if I cache GET: /polls in AWS S3? So the frontend just needs to grab the JSON from the bucket, and every time I update the
database I just updated the JSON in S3, with this approach, I could reduce the amount of invocations to get the polls to zero, instantaneous, and it can handle an "infinite" amount of requests.

My first reaction for this approach was exactly this gif.
But using the 'AWS S3' solution looks pretty ugly, we're engineers, there must be a "better" option.
So I remember from AWS Cloudfront, if we can cache files, we can cache API requests because the return of a request is just a text file with the format that the system knows, JSON.
We could use the max-age and Cache-Control headers to keep the data in AWS Cloudfront for a few seconds until we need to make the request to my API.
With this setup only one request every 3s will ideally reach my API instead of all requests hitting the API the old fashioned way.
I said ideally because cloudfare will cache on the edge, if two people in different parts of the globe make a request, we still need to make two requests because the servers it will be different, and this is called eventual consistency and for what I was building this is not an issue.
Okay, looks good, but what about the votes, another hot path from my code, what can I do with this guy? So I started thinking about that phrase again
and found a solution with AWS SQS and AWS API Gateway HTTP.
Did you know that you can expose an SQS queue directly with Api Gateway?
I didn't know either, with this guy, essentially anyone can send an item into the queue.
For me this was perfect because it was exactly what I needed, but I had my API to handle it directly, so if I use this integration I can reduce the number of requests to zero
accessing my API to vote, not to process the votes, perfect!
And with SQS Lambda Integration, we can configure Batch Window, which you can configure to AWS to group the items in the queue until they reach X amount every Y seconds before calling something to process it.
In my case, I set it to process 300 items in 3s, because I have A LOT of votes, we get more than that in 1s so 3s is very safe. Also, I couldn't set more than 300 because
the lambda didn't support that amount of data, so 300 was my limit.
Another advantage of this queued solution, I can do a batch insert into the database, which is much faster than doing an insert for each item.
In the end, instead of writing an insert for every vote, I just write an insert for every 300 votes.
Finally, remember how I said that it doesn't matter which database API technology I choose? That's why, with this kind of caching and using queue and batch inserts, it doesn't matter if I do it with NoSQL, C#, C++, whatever the technology, because those improvements will only be a fraction of the total time saved by choosing the right strategy for the job.
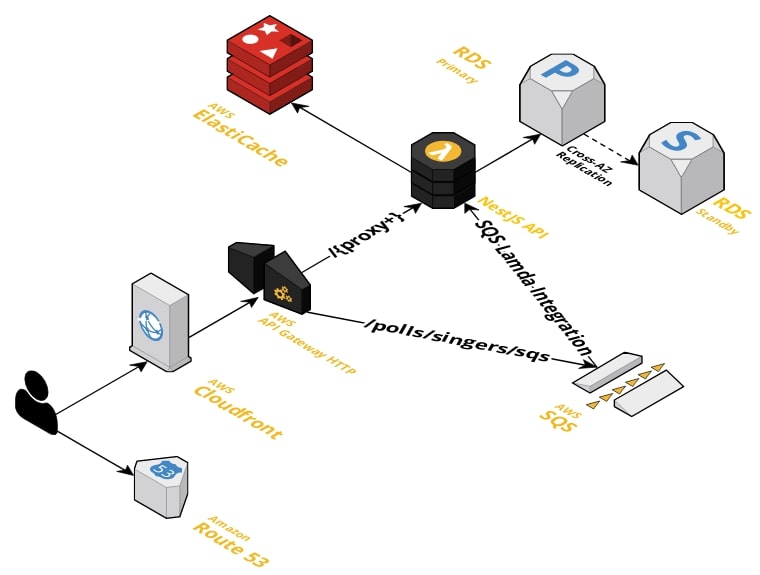
v2 Architecture
Okay, let's summarize our new architecture:
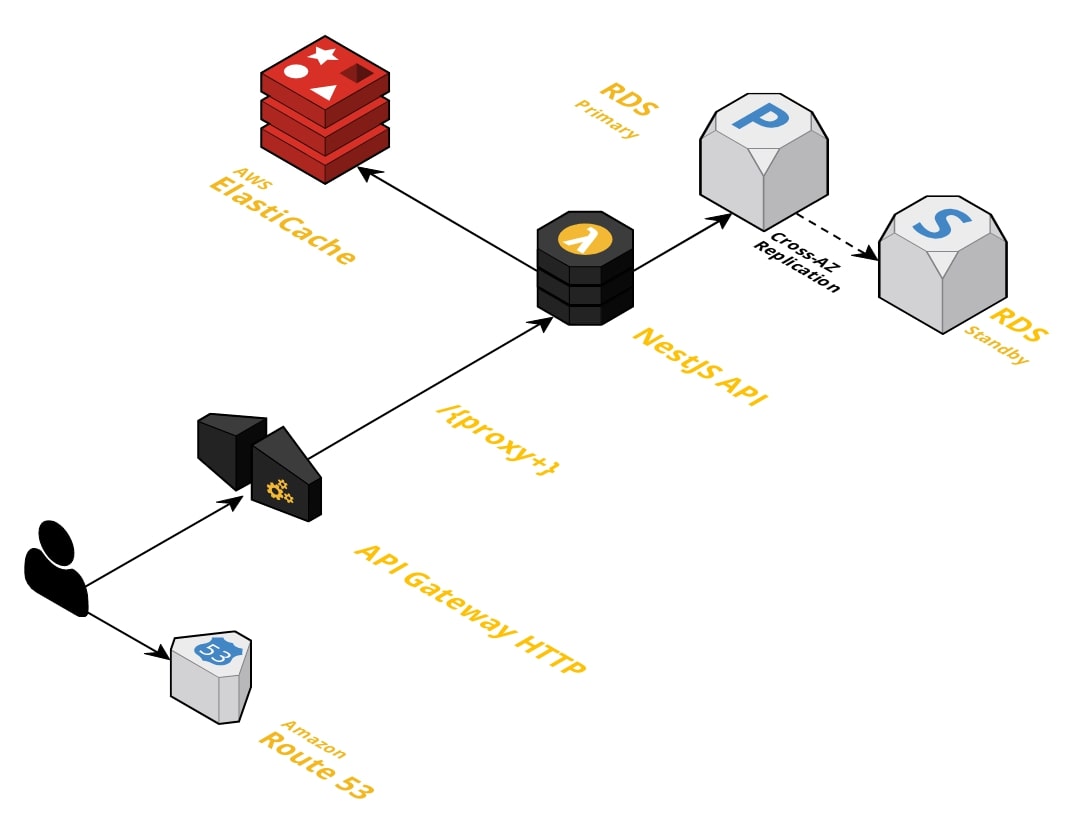
For /polls: we will use AWS Cloudfront in front of AWS API Gateway and the API will return Cache-Control: s-max-age=3s to cache the data for 3s until Cloudfront needs it to access the API again.
For /polls/{pollId}/signers/{signerId}: Let's change this route to /polls/signers/sqs and configure within the API Gateway to forward directly to the SQS queue.
So every time someone sends a request to /polls/signers/sqs it will call SQS directly and not call my API.
Then I configure SQS to call my Lambda using Serverless-adapter and SQS Adapter,
which will turn the SQS event into an HTTP Post request to my API to allow us to keep the logic in the same codebase.
Within the code, we can use the same strategy of doing validations with ElastiCache and in the end, just do a batch insert in the database.
Now the architecture looks like this:
The metrics of V2
Well, the most exciting part of doing some optimization is seeing the metrics, to check if they really helped.
Let's see the metrics for 700k votes in stress tests:

And for the database, we have these metrics.
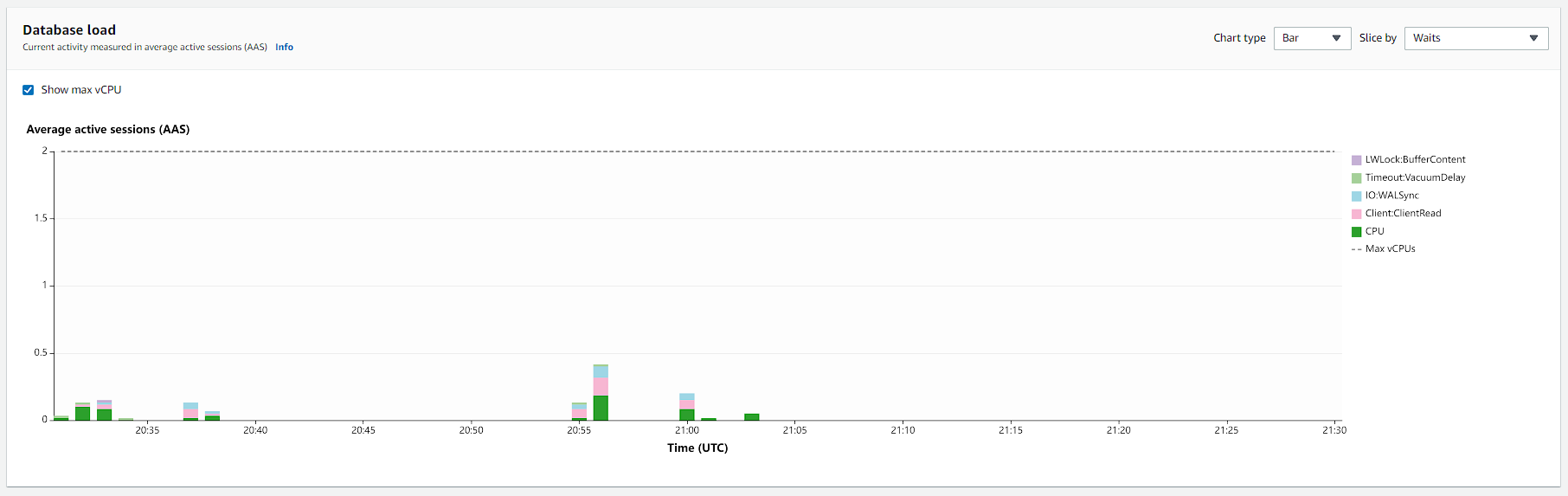
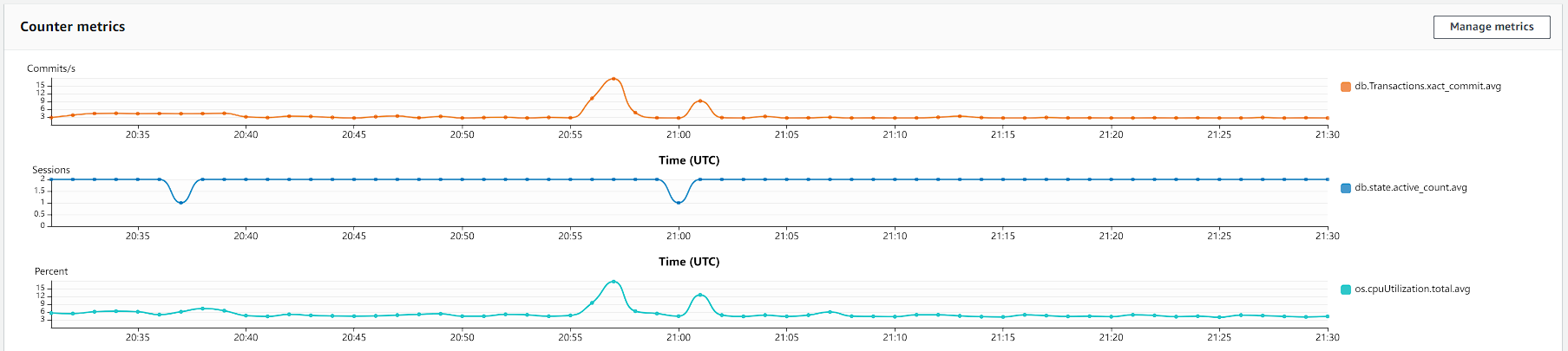
Hint: Click on the image to open in higher resolution.
To summarize:
| Version | Num. of Votes | Invocations (peak) | Concurrency (peak) | Number of vCPU | CPU Usage (peak) | RDS Commits (peak) |
|---|---|---|---|---|---|---|
| v1 | 280k | 1,51 million | 200 | 1,5 | 40% | 400 commit/s |
| v2 | 700k | 1,6 thousand | 11 | 0,5 | 15% | 15 commit/s |
Conclusion
I hope that with this article you can learn something about AWS Cloudfront, AWS SQS and AWS API Gateway, about how correct caching can optimize your application and how Batch can be much more efficient than doing one thing at a time.
Also, not just about technologies, I hope you've learned a little bit about the mindset of also looking for improvements to reduce costs, improve scalability and availability of the system you're working on. And most importantly, never be satisfied with something just because it works, everything could be improved, you just haven't learned how to improve yet.
Also, as a developer, always read the documentation for your company's cloud services so you can identify improvements like these. I'm not telling you to get the cloud certificate, but sometimes just read the documentation and see what they can do, do little experiments to see what advantages it can bring to a project you're working on, in my case it reduced it a lot costs and greatly improved scalability.
Lastly, a tip on how to use these services, monitor usage and put limits on your API Gateway, scalable solutions are great until the bill comes (: